
一、简述
IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄。一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。IO 是指网络 IO,多路指多个TCP连接(即 socket 或者 channel),复用指复用一个或几个线程。
意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。IO 多路复用的三种实现方式:select、poll、epoll。
二、select 机制
1️⃣基本原理:
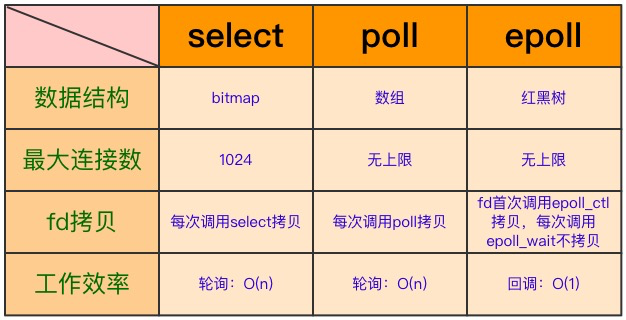
客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和 exceptfds(异常)。select 会阻塞住监视 3 类文件描述符,等有数据、可读、可写、出异常或超时就会返回;返回后通过遍历 fdset 整个数组来找到就绪的描述符 fd,然后进行对应的 IO 操作。
2️⃣优点:
几乎在所有的平台上支持,跨平台支持性好
3️⃣缺点:
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
单个进程打开的 FD 是有限制(通过FD_SETSIZE设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
三、poll 机制
1️⃣基本原理与 select 一致,也是轮询+遍历。唯一的区别就是 poll 没有最大文件描述符限制(使用链表的方式存储 fd)。
2️⃣poll 缺点
由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
四、epoll 机制
1️⃣基本原理:
没有 fd 个数限制,用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过 epoll_ctl 注册 fd,一旦 fd 就绪就会通过 callback 回调机制来激活对应 fd,进行相关的 io 操作。epoll 之所以高性能是得益于它的三个函数:
epoll_create() 系统启动时,在 Linux 内核里面申请一个B+树结构文件系统,返回 epoll 对象,也是一个 fd。
epoll_ctl() 每新建一个连接,都通过该函数操作 epoll 对象,在这个对象里面修改添加删除对应的链接 fd,绑定一个 callback 函数
epoll_wait() 轮训所有的 callback 集合,并完成对应的 IO 操作
2️⃣优点:
没 fd 这个限制,所支持的 FD 上限是操作系统的最大文件句柄数,1G 内存大概支持 10 万个句柄。效率提高,使用回调通知而不是轮询的方式,不会随着 FD 数目的增加效率下降。内核和用户空间 mmap 同一块内存实现(mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间)
3️⃣epoll缺点:
epoll 只能工作在linux下。
4️⃣epoll 应用:redis、nginx
五、epoll 水平触发(LT)与边缘触发(ET)的区别
epoll 有 epoll LT 和 epoll ET 两种触发模式,LT 是默认的模式,ET 是“高速”模式。
1️⃣LT 模式下,只要这个 fd 还有数据可读,每次 epoll_wait 都会返回它的事件,提醒用户程序去操作。
2️⃣ET 模式下,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无论 fd 中是否还有数据可读。所以在 ET 模式下,read 一个 fd 的时候一定要把它的 buffer 读完,或者遇到 EAGAIN 错误。
六、select/poll/epoll 之间的区别
七、为什么有 IO 多路复用机制
没有 IO 多路复用机制时,有 BIO、NIO 两种实现方式,但有一些问题。
1️⃣同步阻塞(BIO)
服务端采用单线程,当 accept 一个请求后,在 recv 或 send 调用阻塞时,将无法 accept 其他请求(必须等上一个请求 recv 或 send 完),无法处理并发。
服务器端采用多线程,当 accept 一个请求后,开启线程进行 recv,可以完成并发处理,但随着请求数增加需要增加系统线程,大量的线程占用很大的内存空间,并且线程切换会带来很大的开销,10000 个线程真正发生读写事件的线程数不会超过 20%,每次 accept 都开一个线程也是一种资源浪费。
2️⃣同步非阻塞(NIO)
服务器端当 accept 一个请求后,加入 fds 集合,每次轮询一遍 fds 集合 recv(非阻塞)数据,没有数据则立即返回错误,每次轮询所有 fd(包括没有发生读写事件的fd)会很浪费 cpu。
3️⃣IO 多路复用
服务器端采用单线程通过 select/epoll 等系统调用获取 fd 列表,遍历有事件的 fd 进行 accept/recv/send,使其能支持更多的并发连接请求。
八、理解 IO 多路复用机制
小王在 S 城开了一家快递店,负责同城快送服务。小王因为资金限制,雇佣了一批快递员,然后小王发现资金不够了,只够买一辆车送快递。
1️⃣【经营方式一】
客户每送来一份快递,小王就让一个快递员盯着,然后快递员开车去送快递。慢慢的小王就发现了这种经营方式存在下述问题:
几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递。
随着快递的增多,快递员也越来越多,小王发现快递店里越来越挤,没办法雇佣新的快递员了。
快递员之间的协调很费时间。
2️⃣【经营方式二】
小王只雇佣一个快递员。然后呢,客户送来的快递,小王按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。
3️⃣【对比】
两种经营方式对比,第二种明显效率更高,更好。在上述比喻中:
每个快递员------------------>每个线程
每个快递-------------------->每个socket(IO流)
快递的送达地点-------------->socket的不同状态
客户送快递请求-------------->来自客户端的请求
小王的经营方式-------------->服务端运行的代码
一辆车---------------------->CPU的核数
4️⃣ 于是有如下结论:
【经营方式一】就是传统的并发模型,每个 IO 流(快递)都有一个新的线程(快递员)管理。
【经营方式二】就是 IO 多路复用。只有单个线程(一个快递员),通过跟踪每个 IO 流的状态(每个快递的送达地点),来管理多个 IO 流。
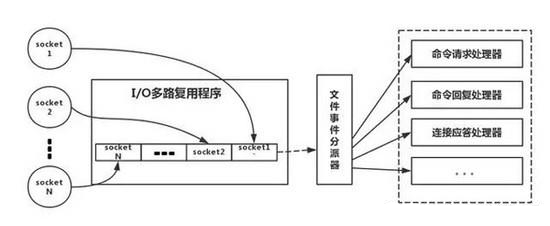
类比到真实的redis线程模型如图。简言之,就是 redis-client 在操作的时候,会产生具有不同事件类型的 socket。在服务端,有一段 IO 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。需要说明的是,这个 IO 多路复用机制,redis 还提供了 select、epoll、evport、kqueue 等多路复用函数库。
九、示例
100 万个连接,里面有 1 万个连接是活跃,可以对比 select、poll、epoll 的性能表现:
1️⃣select:不修改宏定义默认是 1024,则需要100w/1024=977个进程才可以支持 100 万连接,会使得 CPU 性能特别的差。
2️⃣poll:没有最大文件描述符限制,100 万个链接则需要 100 万个 fd,遍历都响应不过来了,还有空间的拷贝消耗大量的资源。
3️⃣epoll:请求进来时就创建 fd 并绑定一个 callback,只需要遍历 1 万个活跃连接的 callback 即可,既高效又不用内存拷贝。
————————————————
版权声明:本文为CSDN博主「JFS_Study」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ChineseSoftware/article/details/123812179








0条评论
点击登录参与评论