
1.分库分表产生的背景
采用单数据库存储存在以下的性能瓶颈:
①IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。请求数据太多,带宽不够,网络IO瓶颈。
②CPU瓶颈:排序,分组,连接查询,聚合统计等SQL会消耗大量的CPU资源,请求数太多,CPU出现瓶颈。
分库分表将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题。
2.拆分策略:
水平拆分:水平分表,水平分库;
垂直拆分:垂直分表,垂直分库。
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。特点:①每个库的表结构都不一样;②每个库的数据也不一样;③所有库的并集是全量数据。下图为垂直分库案例。

垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。特点:①每个表的结构都不一样;②每个表的数据也不一样,一般通过一列(主键/外键)关联;③所有表的并集是全量数据。下图为垂直分表的案例,两张表以主键id关联。
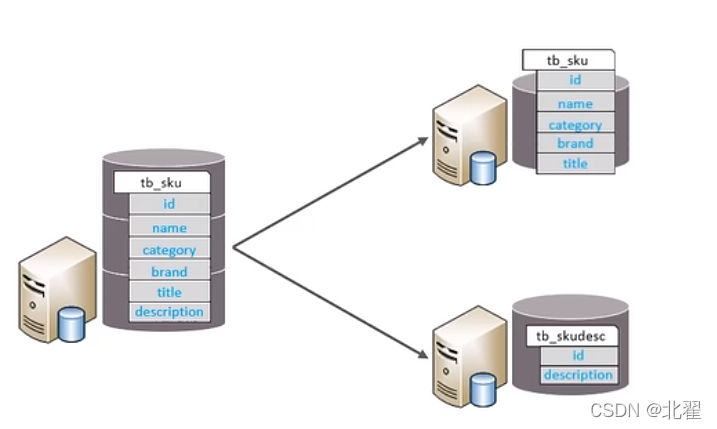
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。特点:①每个库的表结构都一样;②每个库的数据都不一样;③所有库的并集是全量数据。下图为水平分库。
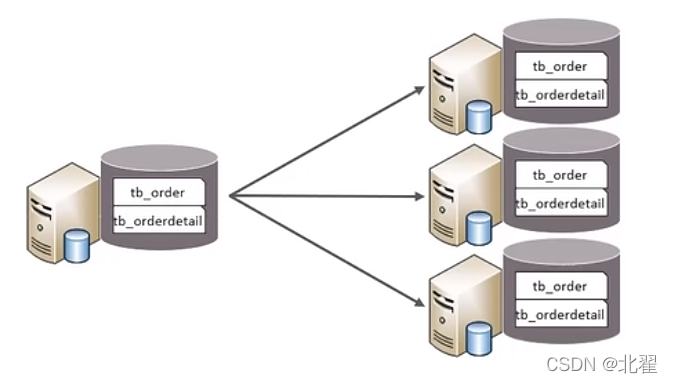
水平分表:以字段为依据,按照一定的策略,将一个表的数据拆分到多个表中。特点:①每个表的表结构都一样;②每个表的数据都不一样;③所有表的并集是全量数据。下图为水平分表。

3.分库分表的实现技术
shardingJDBC:基于AOP原理,在应用程序对本地执行的SQL进行拦截,解析,改写,路由处理。需要自行编码配置实现,支持java语言,性能较高。
MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及shardingJDBC。
4.MyCat
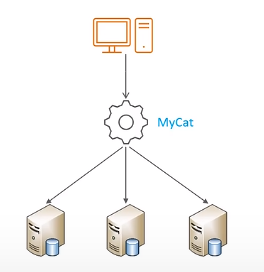
MyCat是一个数据库中间件,使用MyCat也很简单,把我们之前连接数据库换成连接MyCat即可。
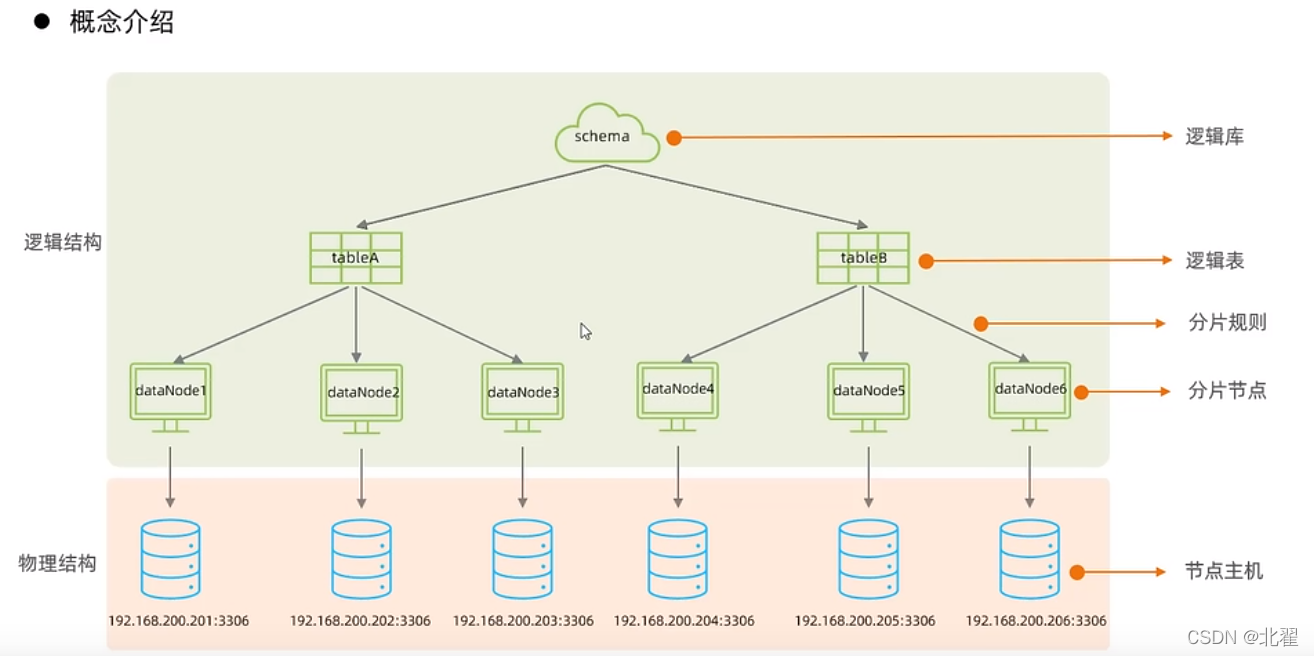
mycat的核心概念:mycat中不存储数据,数据都是存储在节点主机中的,依照分片规则来决定存储在哪个节点主机;mycat只是一个逻辑结构,它是无感知的。
5.mycat分片配置
schema.xml涵盖了mycat的逻辑库,逻辑表,分片规则,分片节点及数据源的配置。主要包含三组标签:schema标签,datanode标签,datahost标签

配置完schema.xml后,还要修改同级目录的server.xml文件,将schemas换成我们配置的schema;
server.xml配置文件包含了mycat的系统配置信息,主要有两个重要标签:system,user

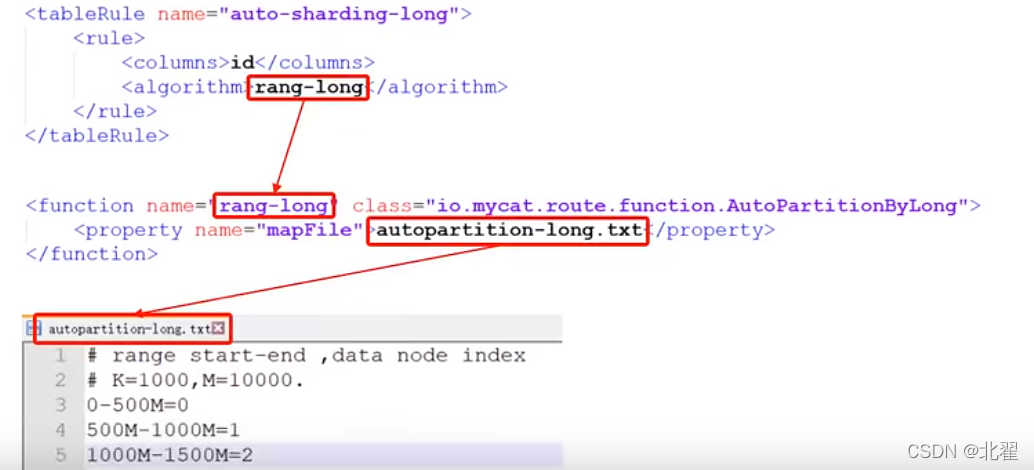
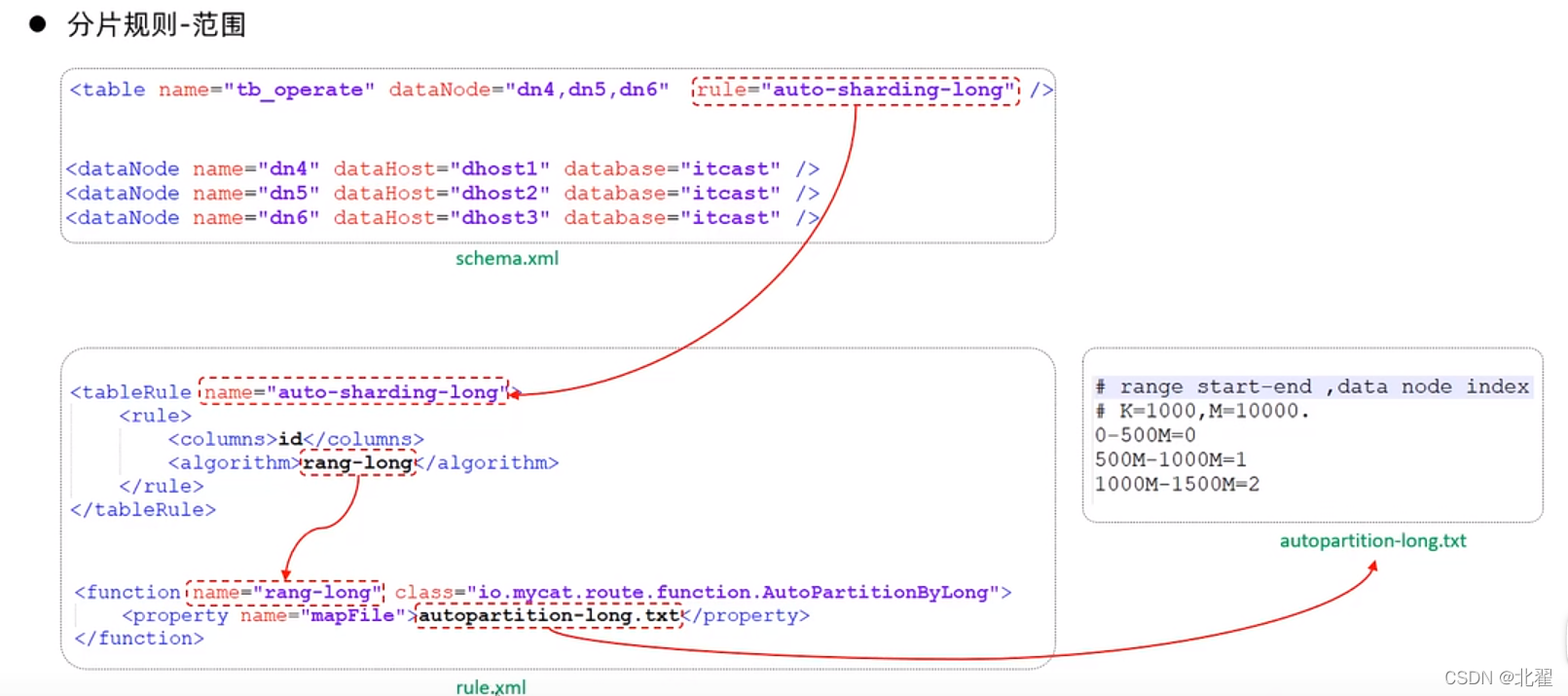
rule.xml中定义所有拆分表的规则,在使用过程中可以灵活使用分片算法,或对同一个分片算法使用不同的参数,它让分片过程可配置化,主要保护局两类标签:tableRule,function。
6.mycat启动
mycat启动后,占用端口8066。
7.mycat分片
垂直分库
mycat分片情况下,涉及跨库查询(跨分片查询)会报错,因为mycat无法确定该SQL应该路由到哪个分片。
解决方案:将涉及的表设置为全局表(在schema.xml中table标签加上type='global',dataNode为所有的节点),mycat对全局表任意节点进行DML时,所有节点都会同步进行
水平分表
水平分表的核心在于分片规则,只有水平分表才需要填写分片规则。
8.常见的分片规则:
范围分片:根据指定的字段及其配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。rule='auto-sharding-long';
取模分片:根据指定的字段与节点数量进行求模运算,根据运算结果,来决定该数据属于哪一个分片。rule='mod-long';

一致性hash分片:根据指定的字段,算出字段的hash值,根据运算结果,来决定该数据属于哪一个分片。rule='sharding-by-murmur';

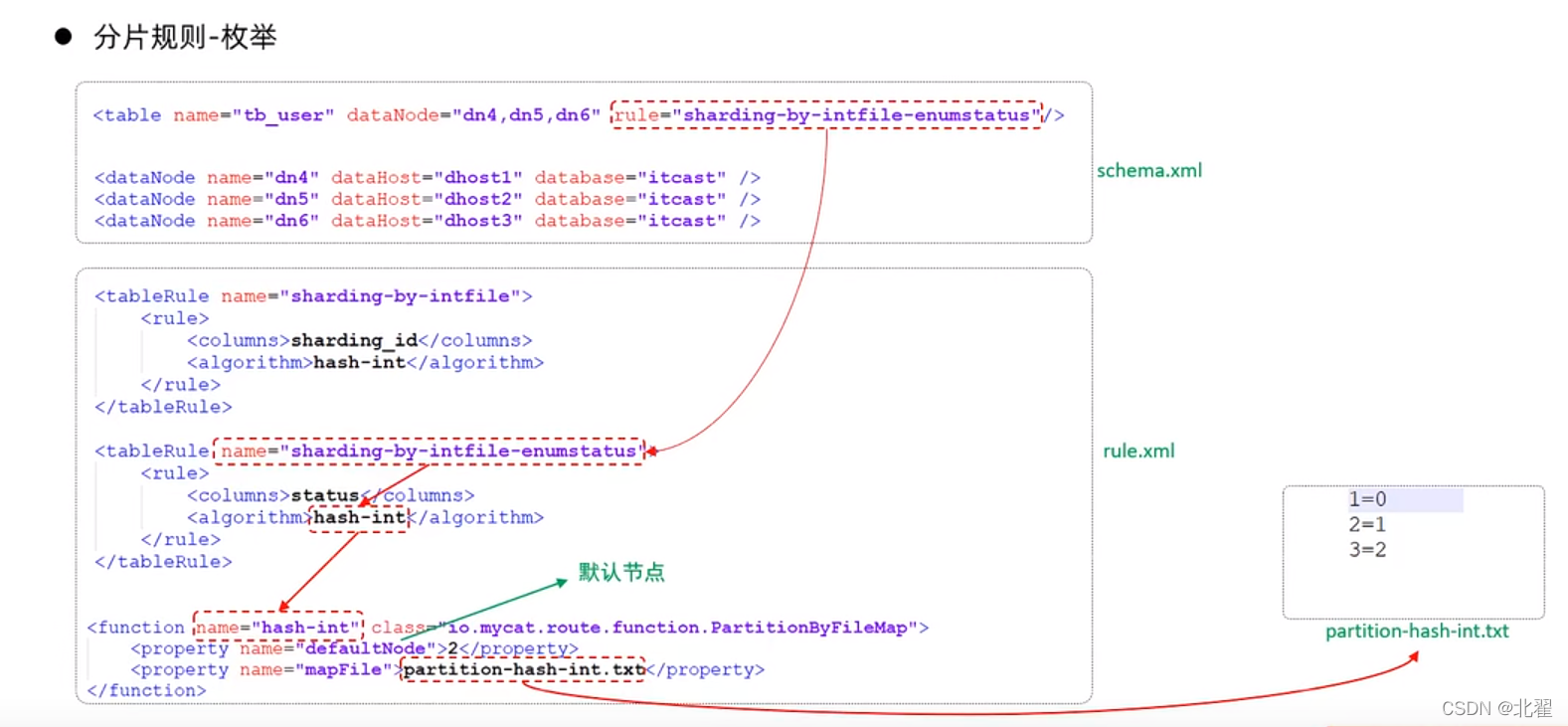
枚举分片:通过在配置文件中配置可能的枚举值,指定数据分布到不同数据节点上,本规则适用于按照省份,性别,状态拆分数据等业务。rule='sharding-by-intfile-enumstatus';
超过枚举值的数据要指定一个节点存储。
应用指定分片:运行阶段由应用自主决定路由到哪个分片,直接根据字符串(必须是数字)计算分片号。rule='sharding-by-substring';

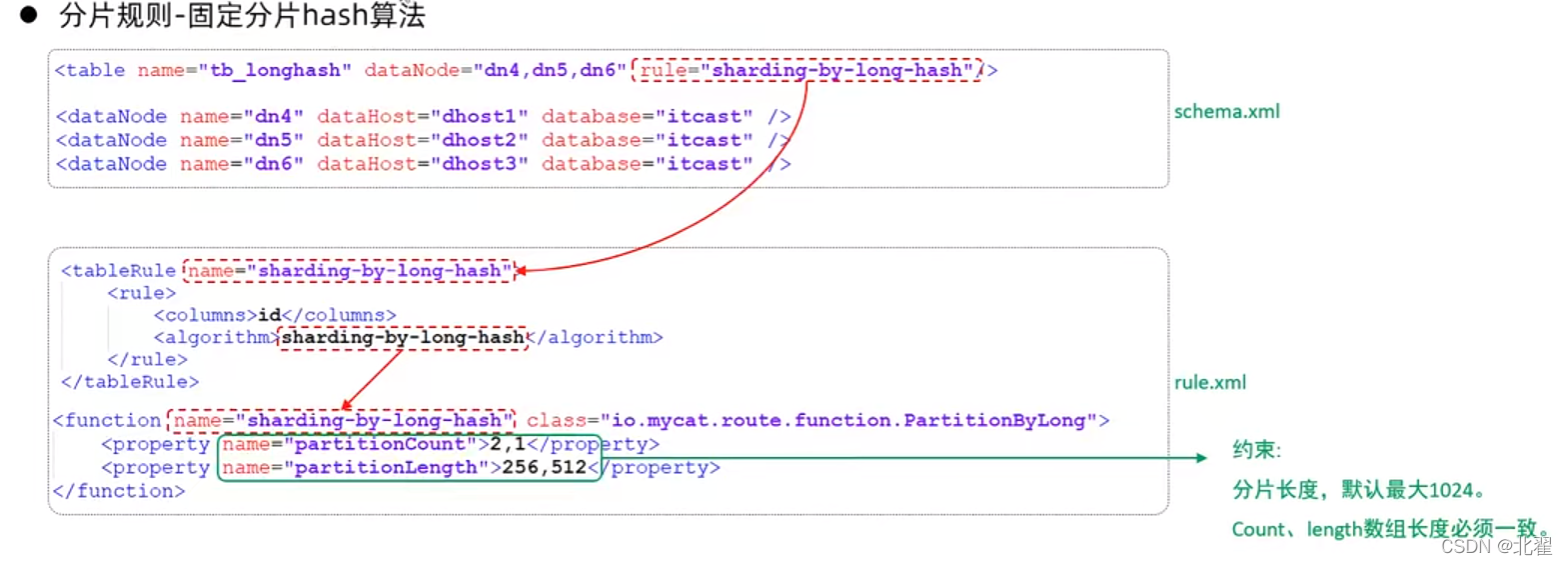
固定分片hash算法:该运算类似于十进制的求模运算。例如:取id的二进制低10位与1111111111进行位&运算。rule='sharding-by-long-hash';
位&运算:同为1则为1,有一个0则为0。例如:
1010101010&1111111111 = 1010101010
特点:①如果是求模,连续的值分别分配到各个不同的分片,但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度;②可以均匀分配,也可以非均匀分配;③分片字段必须为数字类型
字符串hash解析分片:截取字符串中的指定位置的字符串,进行hash算法,算出分片。rule='sharding-by-stringhash';
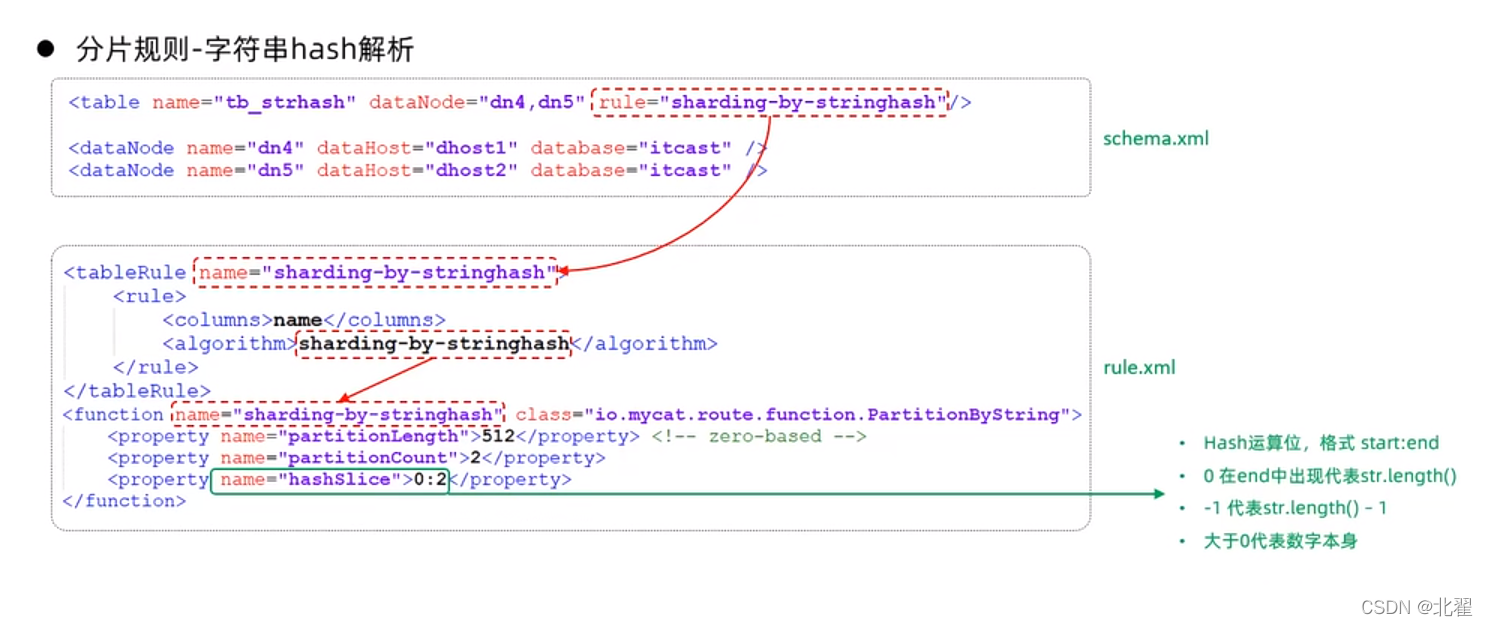
按(天)日期分片:从开始时间开始,每10天(可以自行设置)为一个分片,到达结束时间后,会重复开始分片插入。rule='sharding-by-date';
配置表的DataNode的分片,必须和分片规则数量一致,例如2022-01-01到2022-12-31,每10天一个分片,一共需要37个分片。因此,开始日期和结束日期一定要注意选择。

按自然月分片:按照月份分片,每个自然月为一个分片。rule='sharding-by-month';
配置表的DataNode的分片,必须和分片规则数量一致,例如2022-01-01到2022-12-31,一共需要12个分片。因此,开始日期和结束日期一定要注意选择。

9.mycat的监控与管理
9.1、mycat的原理
每一个节点都只存储了一部分数据,因此,聚合处理、排序处理和分页处理等在各个节点处理是没有任何意义的,mycat会先将查询的结果合并然后再进行处理。

9.2、mycat管理
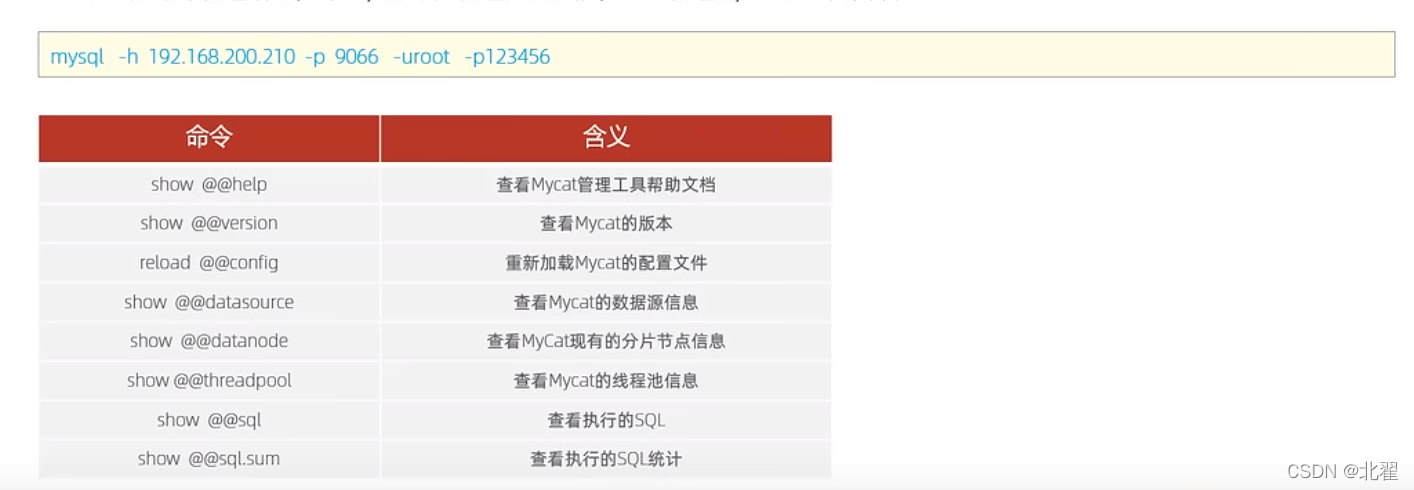
mycat默认开通2个端口,可以在server.xml中进行修改。8066数据访问端口和9066数据库管理端口。
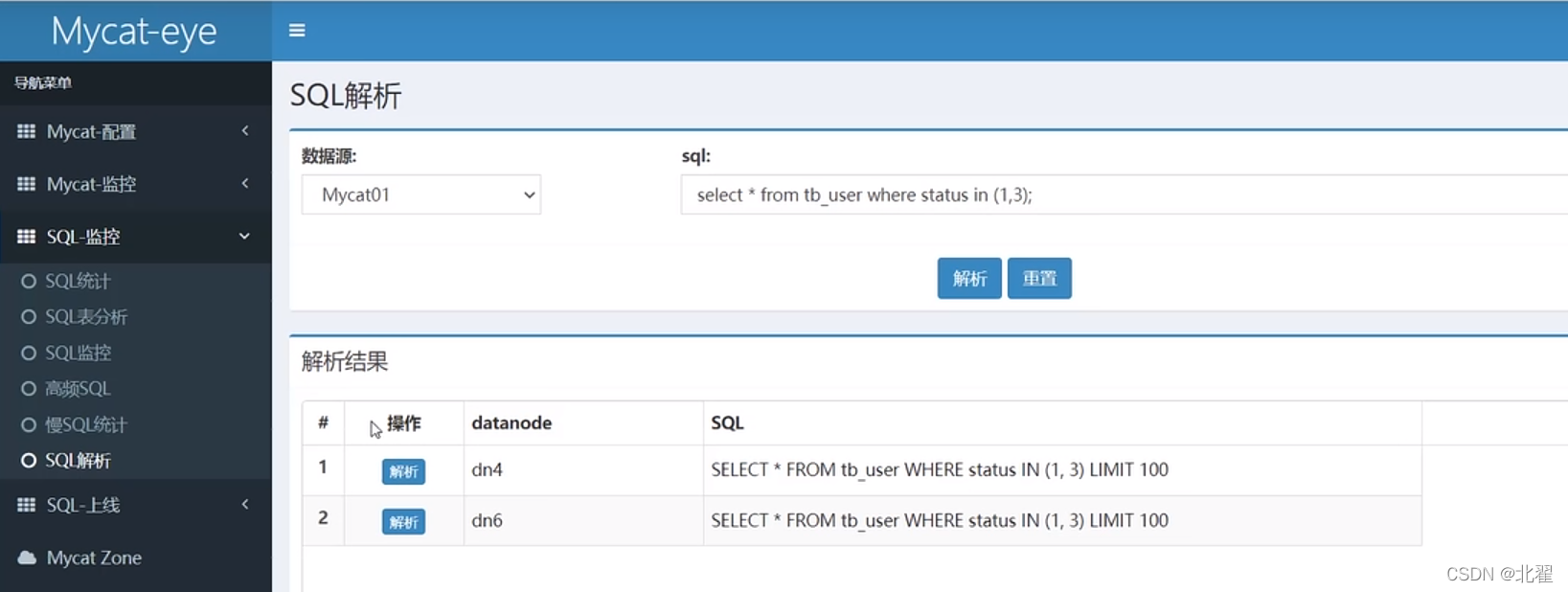
9.3、mycat图形化界面mycat-eye
mycat-eye是对mycat-server提供监控服务,功能不局限于对mycat-server使用,通过JDBC连接对mycat,mysql监控,监控远程服务器(目前仅限于linux系统)的cpu、内存、网络、磁盘。
mycat-eye运行过程中需要依赖zookeeper,因此需要先安装zookeeper。
————————————————
版权声明:本文为CSDN博主「北翟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39757139/article/details/123470471









0条评论
点击登录参与评论